2023年DevOps团队值得关注的10大开源监控工具
在2023年,监控平台对于现代DevOps团队的工作至关重要。DevOps团队需要可靠且灵活的工具,以有效地监控和管理复杂的系统,并提供实时的系统性能、可用性和安全性洞察。
在2023年,监控平台对于现代DevOps团队的工作至关重要。DevOps团队需要可靠且灵活的工具,以有效地监控和管理复杂的系统,并提供实时的系统性能、可用性和安全性洞察。
由于其成本效益、灵活性和社区支持,开源监控工具变得越来越受欢迎。
开源监控工具的优缺点
以下是与SaaS工具相比,开源监控工具的一些优点和缺点。
优点
- 定制化:开源监控工具可以在监控配置和与其他工具的集成方面提供更大的定制化和灵活性。
- 成本效益:开源工具通常是免费或低成本的,使其成为预算有限的组织的经济实惠解决方案。
- 透明度:开源监控工具的代码可以公开审查和审核,提供更大的透明度和问责制。
- 社区支持:开源监控工具通常得到大量开发者社区的支持,他们提供支持并为工具的发展做出贡献。
缺点
- 复杂性:与SaaS监控工具相比,开源工具通常需要更多的技术专长和努力来安装、配置和维护。
- 支持:虽然有社区支持可用,但对于具有复杂或专门化监控需求的组织来说,这可能不足够。
- 安全性:开源工具可能容易受到安全漏洞的影响,因为它们可能缺乏SaaS工具提供的强大安全功能和更新。
- 可扩展性:与SaaS工具相比,开源监控工具可能不够可扩展,因为它们可能需要额外的硬件和基础设施来实现有效的扩展。
十大开源监控工具
我们将介绍现代DevOps团队在2023年应该注意的以下开源监控工具:
- Sensu Go
- SigNoz
- Elastic APM
- Jaeger
- Prometheus
- Grafana
- OpenTelemetry
- Zabbix
- Healthchecks.io
- Percona Monitoring and Management (PMM)
这些工具提供了一系列的监控功能,包括收集和分析指标、监控日志、追踪请求和警报。每种工具都有其优势和劣势,对于特定的DevOps团队来说,最好的选择将取决于他们独特的需求和要求。
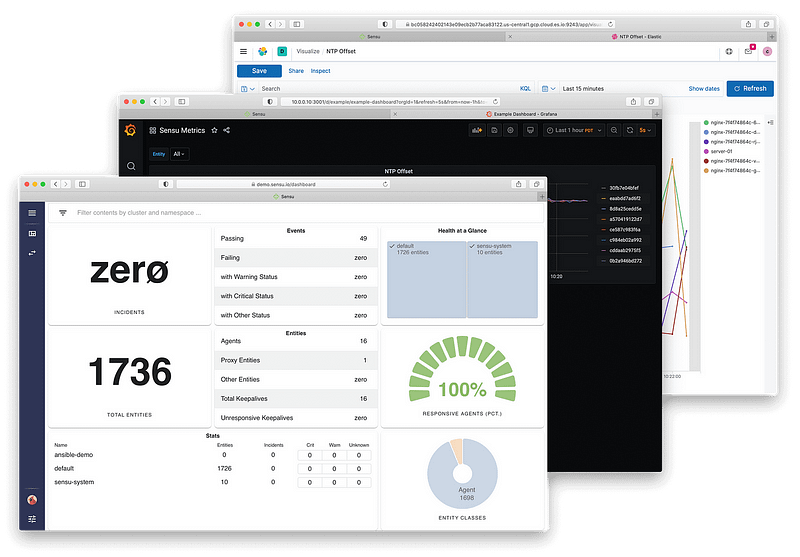
Sensu Go
Sensu Go是一个开源的监控工具,允许你监控你的基础设施,包括服务器、容器和云服务。Sensu有3个关键点: 简单,可扩展,和多云监控。
Sensu Go使用分散的架构,监控检查在称为代理的客户端节点上执行,结果被发送到后台服务器进行处理和存储。这种架构允许更灵活和可扩展的监控设置,你可以根据需要添加或删除代理,并在你的基础设施上分配监控工作量。
Sensu提供了监控即代码的功能和自动化,这对这种动态环境是至关重要的,从基于监控代码模板(YAML配置文件)的完全自动化部署,到控制监控平台所有元素的灵活API。
Sensu Go支持各种类型的监控检查,包括Nagios风格的检查,自定义脚本,以及用各种语言编写的插件。你也可以使用Sensu Go来监控容器化环境,如Kubernetes和Docker,以及云服务,如AWS和GCP。
优点
- 开发人员可以编写自己的监控项
- 配置简单,扩展性好,性能好
- 消息路由
- 兼容Nagios插件
- 使用go语言编写
缺点
- UI不是很好
- Sensu Go有一个学习曲线,用户可能需要一些时间来熟悉其功能和配置选项。
SigNoz
SigNotz是一个开源的APM(应用性能监控)工具,你可以用它来替代Datadog和NewRelic等其他工具。它在监控你的应用程序和排查问题时可以非常方便。
此外,SigNoz集成了OpenTelemetry,支持实现它的各种语言和框架,如Java、Ruby、Python、Elixir等等。它支持各种现代技术和框架,如Kubernetes、Istio、Envoy、Kafka、gRPC等等。
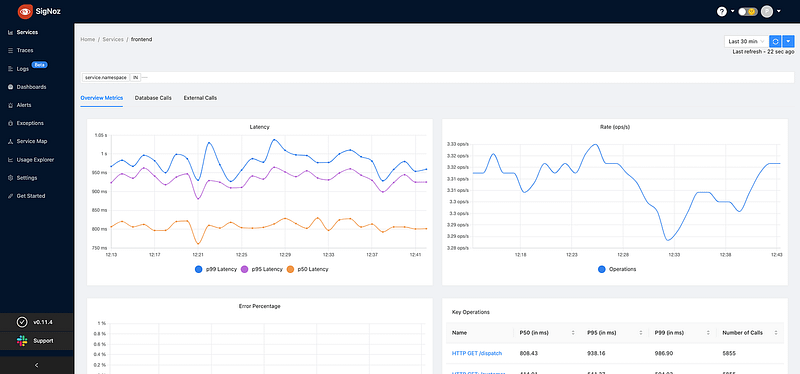
主要功能
- 监测应用指标,如延迟、每秒请求、错误率。
- 监测基础设施指标,如CPU利用率或内存使用。
- 追踪跨服务的用户请求。
- 对指标设置警报。
- 找出问题的根本原因,准确找到造成问题的蛛丝马迹。
- 查看单个请求痕迹的详细火焰图。
Elastic APM
Elastic APM(应用性能监控)是Elastic Stack的一部分,是一套开源的数据分析和可视化工具。Elastic APM旨在为开发人员和DevOps团队提供对其应用程序性能的实时洞察。
Elastic APM支持许多编程语言和框架,包括Java、Python、Ruby、Node.js等。它可以监测应用程序的性能指标,如响应时间、吞吐量、错误率和资源利用率。它还可以提供详细的事务追踪,让开发人员识别他们代码中的瓶颈和性能问题。
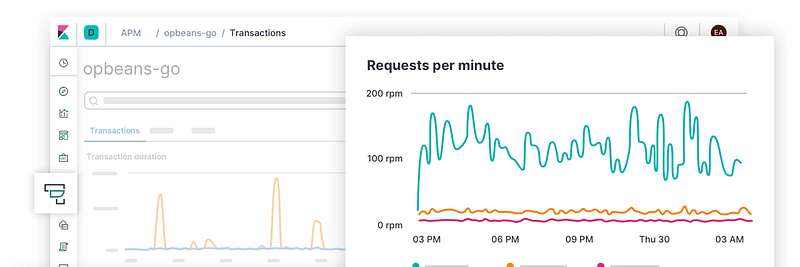
主要功能
- Elastic APM还自动收集未处理的错误和异常。错误主要根据堆栈跟踪进行分组,这样你就可以在新的错误出现时识别它们,并关注特定错误发生的次数。
- 在调试生产系统时,指标是另一个重要的信息来源。
- Elastic APM代理会自动获取基本的主机级指标和代理的特定指标,如Java代理中的JVM指标和Go代理中的Go运行时指标,以及其他许多此类代理。
Elastic APM Github repository →
Jaeger
Jaeger提供端到端的分布式跟踪,使用户能够跟踪请求在复杂系统中的流动,并识别任何性能瓶颈或错误。
Jaeger支持各种编程语言和框架,包括Java, Python, Ruby, Go等。它可以与Spring Boot和Flask等流行的网络框架集成。
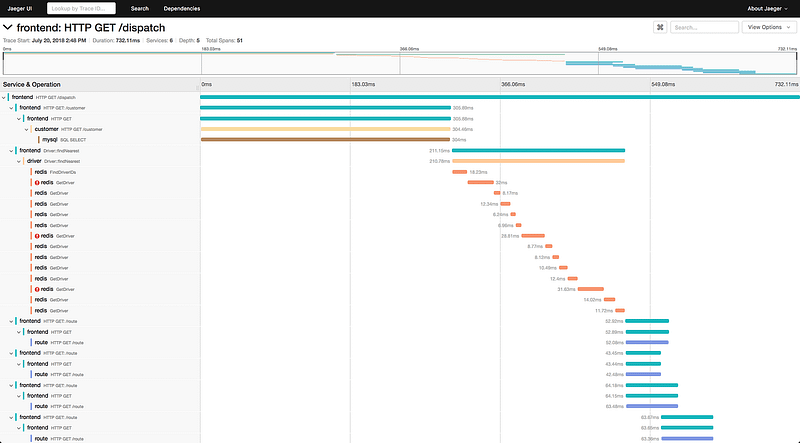
它可用于监测基于微服务的分布式系统:
- 分布式上下文传递
- 分布式事务监控
- 根因分析
- 服务依赖关系分析
- 性能/延时优化
优点
- 易于安装
- 易于配置自选的数据源作为存储后端
- 开源
- 功能丰富的UI
- CNCF 项目
Jaeger在成熟度方面的不足,在速度和灵活性方面得到了弥补,而且它的并行架构更新颖、更分散。它还具有更高的性能,更容易扩展。Jaeger比它的老对手有更好的官方语言支持,你也可以把它对CNCF的支持看作是一个认可的徽章。
Cons
Jaeger的相对不成熟性是一个缺点。Jaeger选择Go作为其主要语言说明了这一点。尽管Gophers正在快速扩展其社区,但它们远没有像Java那样普遍。如果你不熟悉Go,这可能会使你的学习过程更长。
另一个对Jaeger来说既是福又是祸的领域是其更现代的架构。这种架构在性能、可靠性和可扩展性方面提供了好处,但它也远为复杂,更难维护。
Prometheus
Prometheus被设计用来监测广泛的指标,包括应用性能指标、服务器指标和网络指标。它使用一个基于拉动的模型,从应用服务器、数据库和网络设备等目标收集指标。然后,这些指标被存储在一个时间序列数据库中,并可以使用Prometheus Web UI或与Grafana等第三方工具集成进行可视化。
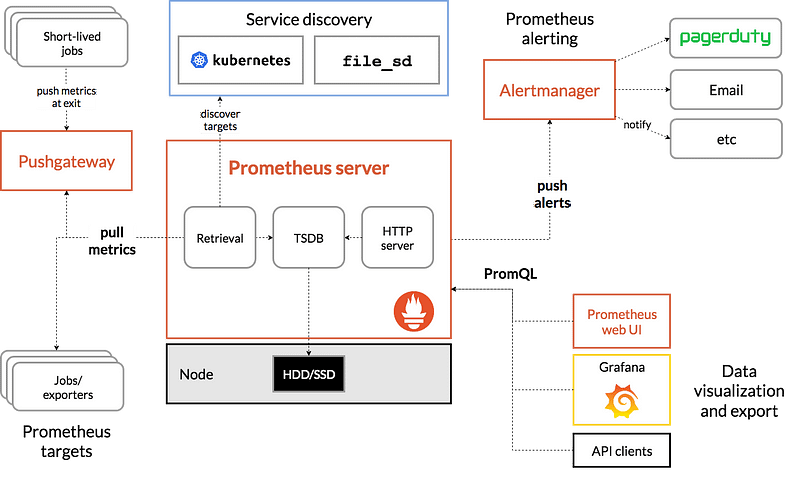
主要功能
- 多维数据模型
- PromQL的查询语言来查询收集到的指标数据。
- 通过HTTP协议采集数据
- 一个处理告警的告警管理器
- 基本的可视化层,但可以与Grafana结合,创建丰富的可视化。
缺点
Prometheus 是一个伟大的指标监测工具,但仅此而已。它不是一个像SigNoz那样的全栈应用监控工具:
- Prometheus只抓取指标。要创建一个强大的监控框架,你需要跟踪指标、日志和痕迹。例如,像SigNoz这样的工具既能捕获指标又能追踪(产品Roadmap中的日志管理)。
- Prometheus是为单机设计的。它不能被横向扩展。
Prometheus Github repository →
Grafana
Grafana提供了一个基于Web的用户界面,用于创建和共享自定义仪表盘,可用于显示和监控关键绩效指标(KPI)和其他指标。Grafana支持广泛的可视化选项,包括图表、图形、仪表和表格,并可用于创建基于指标阈值的自定义警报。
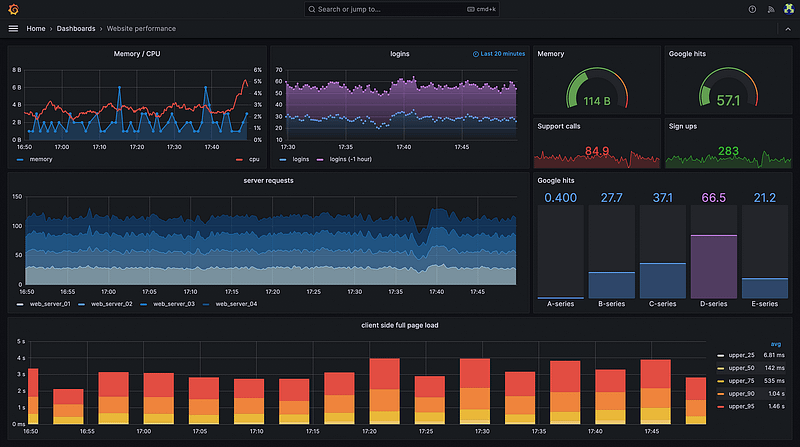
Grafana的主要优势之一是它支持广泛的数据源,包括流行的时间序列数据库,如Prometheus、InfluxDB和Graphite。它还支持Elasticsearch等日志数据源以及AWS和Azure等云厂商。
Grafana包括一个强大的查询编辑器,使用户能够实时过滤、聚合和转换数据。该查询编辑器支持各种查询语言,包括PromQL(由Prometheus使用)、InfluxQL(由InfluxDB使用)和Elasticsearch查询。
优点
- 轻松整合Prometheus和Graphite数据源。
- 许多插件可用于几乎任何存储阵列或操作系统。
- 免费和开源的。如果你想要更多,可以获得专业或高级计划。
- 高度可定制的软件。自定义警报、数据源、仪表板、通知等。
- Grafana是数据可视化的王者。它对来自任何数据源的指标进行绘图。
- 与其他系统协作,发送告警和通知.
缺点
- Grafana的高度可定制属性使其在开始时具有挑战性和耗时性。
- 没有数据存储。如果你还想跟踪历史数据,你就需要一个第三方存储解决方案。
- 你需要熟练掌握JSON和SQL等编程语言,以获得Grafana的最大效益.
OpenTelemetry
OpenTelemetry为各种编程语言和框架提供库,包括Java、Python、Go和.NET。这些库允许开发者以最小的努力来检测他们的应用程序,使其更容易收集遥测数据,如跟踪、度量和日志。
OpenTelemetry使用一个供应商中立的数据模型,允许从多个来源收集遥测数据并输出到多个目的地。这使得它更容易与广泛的可观察性工具和服务集成。
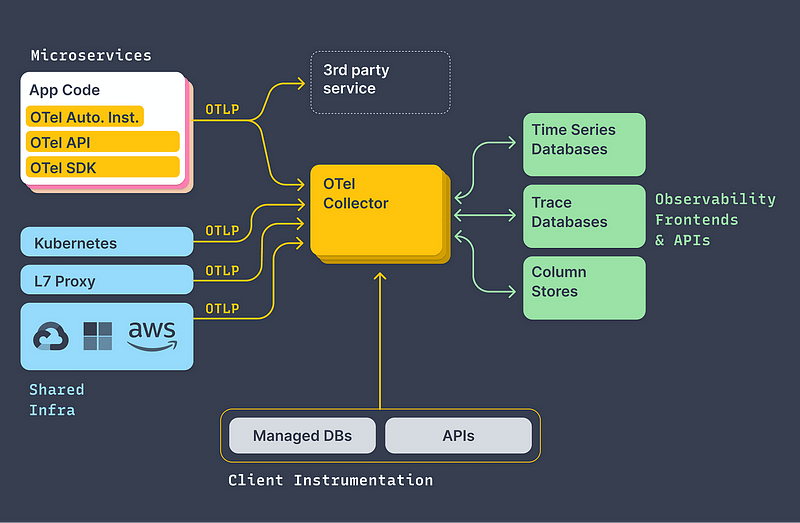
优点
- 减少你的应用程序生成和管理遥测数据的性能开销
- 提供库和代理,以自动测量流行的库和框架,只需对你的代码库做最小的改动。
- 提供OpenTelemetry Collector,它可以接收、处理和输出多种格式的数据
- 得到Google、微软等技术巨头和其他大型云计算厂商的支持。
- 通过使用相关的导出器自由切换到新的后端分析工具
- 对新框架和技术的支持
缺点
- 项目在改进文件和支持方面有很大的空间
- 它不提供后端存储和可视化层
Zabbix
Zabbix使用客户端-服务器架构,Zabbix服务器从安装在网络设备、服务器和应用程序上的多个代理收集数据。它还可以从其他来源收集数据,如SNMP陷阱、JMX计数器和支持IPMI的设备。
Zabbix支持广泛的数据收集方法,包括简单的检查,如ping、HTTP和SMTP检查,以及更高级的检查,如SNMP、JMX和IPMI检查。它还支持自定义检查,可用于监测自定义应用程序和服务的性能。
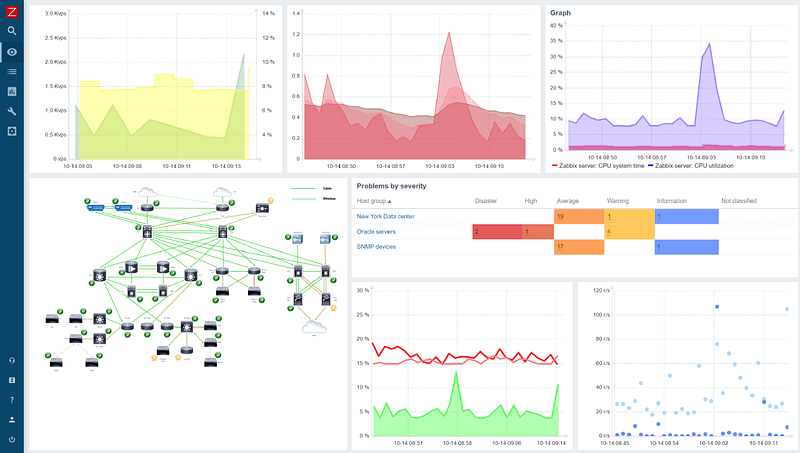
优点
- 丰富的功能,大量可能的集成,开箱即用的模板和多租户支持,强大的API,支持大多数网络、服务器、服务、应用和物联网的监控协议。可以使用标准协议和自定义脚本监控几乎所有的东西。
缺点
- 最初的设置需要大量的工作,从长远来看,还需要大量的优化。文档对于初次使用的人来说不是很清楚,特别是在安装或安装后管理过程中出现的常见问题.
Healthchecks.io
Healthchecks.io是一项用于监控cron作业和类似定期进程的服务。
- Healthchecks.io监听来自你的cron作业和计划任务的HTTP请求(”ping”)。
- 只要PING按时到达,它就保持静默。
- 当一个ping没有及时到达时,它会发出告警。
Healthchecks.io并不适合于:
- 通过对HTTP请求的探测来监测网站的正常运行时间
- 收集应用性能指标
- 日志汇总
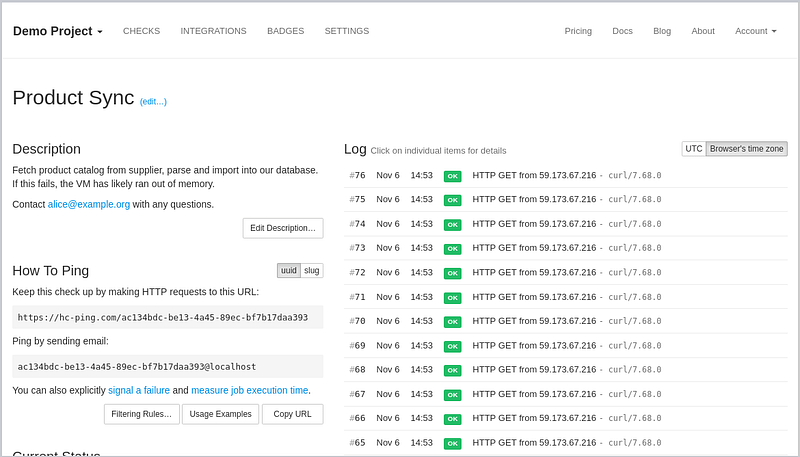
主要功能
- 开源,可以私有部署
- 简单,整洁的Dashboard
- 团队 & API的访问支持
优点
- 该界面的设置极为简单,有明确的实施说明。
- 在5分钟内,当你的服务器无法报告和服务器恢复在线时,你可以得到通知。
- 到了月底,你会有一份电子邮件报告,其中有你的停机时间。
缺点
- 该服务缺乏高级分析和其他高级功能。
- 那些寻求此类功能的人可能会发现它并不适合。然而,我认为这项服务的简单性是一种好处。增加更多的功能有可能会减损出色的用户体验。
Healthchecks.io Github repository →
Percona Monitoring and Management (PMM)
Percona Monitoring and Management(PMM)是一个开源平台,用于管理和监控数据库的性能。Percona监控和管理可用于监控广泛的开源数据库环境:
- Amazon RDS MySQL
- Amazon Aurora MySQL
- MySQL
- MongoDB
- Percona XtraDB Cluster
- PostgreSQL
- ProxySQL
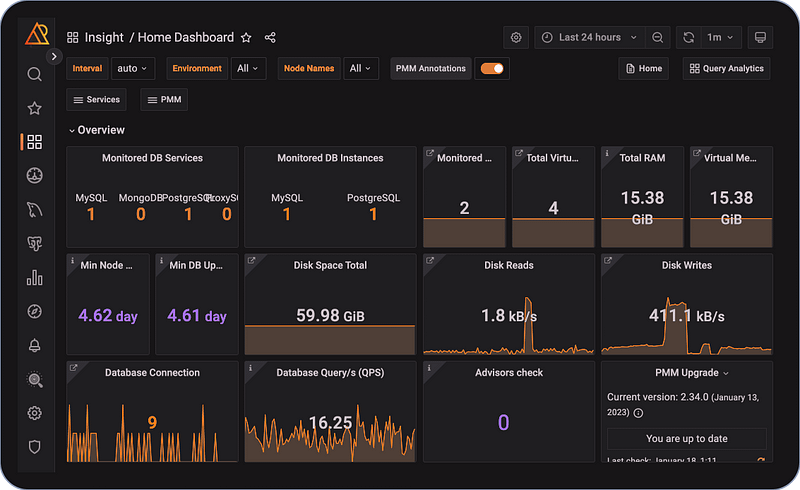
主要功能
- 监测你的数据库基础设施的健康状况
- 探索数据库行为模式
- 管理和提高数据库的性能,无论它们位于何处
- 管理和提高数据库的性能,无论它们位于何处
- 访问控制/权限
- 历史趋势分析
优点
- 集群节点之间性能的可视性。
- 易于使用,界面良好
- 非常深入的数据库指标,如慢速查询日志、性能模式等
缺点
- 应改进警报系统,如警报模板。
- 不能有效地支持庞大的数据库。
结论
今天复杂的技术环境需要灵活的监控工具,既要强大又要有成本效益。开源解决方案,如上面介绍的那些,提供了大量的优势,从透明度和可定制性到成本效益和社区支持。
然而,在为你的DevOps团队选择合适的工具时,考虑诸如系统复杂性、技术专长、可扩展性和预算等因素是很重要的。密切关注这些工具的最新发展和更新,以确保你的团队拥有维护系统性能、可靠性和安全性的最佳资源。
明智地选择,使你的团队拥有做出最佳决策和采取有效行动所需的信息。
感谢您的阅读, 也许你对下列文章也感兴趣: